Apple révolutionne le domaine de l’IA avec son nouveau modèle MM1, qui promet une compréhension multimodale avancée des données.
Une équipe de chercheurs en informatique et ingénieurs chez Apple a développé un modèle LLM que la société affirme capable d’interpréter à la fois les images et les données textuelles. Le groupe a publié un article sur le serveur de prépublication arXiv décrivant leur nouvelle famille de modèles multimodaux MM1 et les résultats des tests.
Au cours de l’année écoulée, les LLM ont beaucoup fait parler d’eux pour leurs capacités avancées en IA. Une entreprise notablement absente de la conversation est Apple. Dans cet nouvel effort, l’équipe de recherche précise que la société ne cherche pas simplement à ajouter un LLM développé par une autre entreprise (actuellement, elles négocient avec Google pour ajouter la technologie Gemini AI aux appareils Apple) ; au lieu de cela, elles ont travaillé au développement d’un LLM de nouvelle génération, capable d’interpréter à la fois les images et les données textuelles.
L’IA multimodale fonctionne en intégrant et en traitant différents types d’entrées de données, telles que des informations visuelles, auditives et textuelles. Cette intégration permet à l’IA d’avoir une compréhension plus complète des données complexes, conduisant à des interprétations plus précises et contextuelles que les systèmes IA à mode unique.
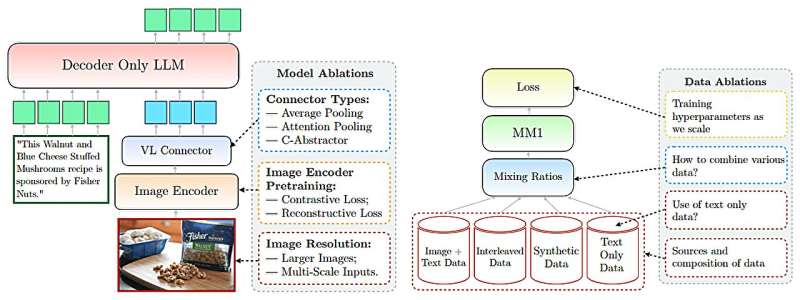
L’équipe de recherche d’Apple affirme avoir réalisé des avancées majeures en utilisant l’IA multimodale avec ses modèles MM1, qui intègrent des données textuelles et d’image pour améliorer les capacités de légendage d’image, de réponse aux questions visuelles et d’apprentissage par interrogation. Leur MM1 fait partie de ce qu’ils décrivent comme une famille de modèles multimodaux, chacun comprenant jusqu’à 30 milliards de paramètres.
Ces modèles, notent les chercheurs, utilisent des ensembles de données comprenant des paires d’images, des documents comprenant des images et des documents textuels uniquement. Les chercheurs affirment en outre que leur LLM multimodal (MLLM) peut compter les objets, identifier les objets faisant partie d’une image et utiliser le bon sens sur les objets de la vie quotidienne pour offrir aux utilisateurs des informations utiles sur ce que présente l’image.
Les chercheurs affirment également que leur MLLM est capable d’apprentissage en contexte, ce qui signifie qu’il n’a pas besoin de recommencer à chaque fois qu’une question est posée ; il utilise ce qu’il a appris dans la conversation actuelle. L’équipe fournit des exemples des capacités avancées de leurs modèles, dont l’un comprend le téléchargement d’une image d’un groupe d’amis dans un bar tenant un menu et demandant au modèle combien cela coûterait d’acheter une bière pour tout le monde en fonction des prix indiqués dans le menu.
1,682 total views, 1 views today